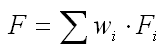Software: SimX - Nadelantrieb - Probabilistik - Moment-Methoden: Unterschied zwischen den Versionen
KKeine Bearbeitungszusammenfassung |
KKeine Bearbeitungszusammenfassung |
||
| Zeile 2: | Zeile 2: | ||
<div align="center">'''Moment-Methoden (Überblick)'''</div> | <div align="center">'''Moment-Methoden (Überblick)'''</div> | ||
Vergleichend zur probabilistischen Simulation mit der '''''Sample-Methode''''' ''Latin Hypercube Sampling'' soll nun der analytische Ansatz der '''''Moment-Methode''''' betrachtet werden: | Vergleichend zur probabilistischen Simulation mit der '''''Sample-Methode''''' ''Latin Hypercube Sampling'' soll nun der analytische Ansatz der '''''Moment-Methode''''' betrachtet werden: | ||
* | * Wir nutzen die vorhandene .opy-Projektdatei '''Etappe4_xx.opy''', welche für das Latin Hypercube Sampling mit 5 Streuungen konfiguriert ist. | ||
* | * Nach dem Öffnen dieser Datei kann man den Experiment-Workflow mit den konfigurierten Entwurfsparameter-Streuungen und den Restriktionen unverändert nutzen. | ||
* | * Alle Analyse-Fenster sollte man definiert schließen, um sich die mit der Moment-Methode verfügbaren Ergebnisse dann schrittweise zu erschließen. | ||
* Die Versuchsplanung müssen wir entsprechend umkonfigurieren. | |||
Bei der Moment-Methode handelt sich um ein analytisches Verfahren. Für jede betrachtete Output-Größe eines Modells wird eine Funktion '''''f''''' gebildet, mit welcher sich der Wert der Output-Größe aus dem Variablenvektor '''''x''''' der '''''n''''' Streugrößen berechnen lässt: | Bei der Moment-Methode handelt sich um ein analytisches Verfahren. Für jede betrachtete Output-Größe eines Modells wird eine Funktion '''''f''''' gebildet, mit welcher sich der Wert der Output-Größe aus dem Variablenvektor '''''x''''' der '''''n''''' Streugrößen berechnen lässt: | ||
Version vom 20. Mai 2024, 17:15 Uhr
Vergleichend zur probabilistischen Simulation mit der Sample-Methode Latin Hypercube Sampling soll nun der analytische Ansatz der Moment-Methode betrachtet werden:
- Wir nutzen die vorhandene .opy-Projektdatei Etappe4_xx.opy, welche für das Latin Hypercube Sampling mit 5 Streuungen konfiguriert ist.
- Nach dem Öffnen dieser Datei kann man den Experiment-Workflow mit den konfigurierten Entwurfsparameter-Streuungen und den Restriktionen unverändert nutzen.
- Alle Analyse-Fenster sollte man definiert schließen, um sich die mit der Moment-Methode verfügbaren Ergebnisse dann schrittweise zu erschließen.
- Die Versuchsplanung müssen wir entsprechend umkonfigurieren.
Bei der Moment-Methode handelt sich um ein analytisches Verfahren. Für jede betrachtete Output-Größe eines Modells wird eine Funktion f gebildet, mit welcher sich der Wert der Output-Größe aus dem Variablenvektor x der n Streugrößen berechnen lässt:
- Für die Approximation jeder dieser Funktionen f wird eine Taylor-Reihe erster bzw. zweiter Ordnung benutzt (Glied 2. Ordnung gelb):
- Wenn Interaktionen zwischen Eingangsgrößen existieren, werden sie paarweise berücksichtigt. Die Ersatzfunktion f wird dafür um ein Glied mit linearen Kreuzableitungen (grün) ergänzt.
- Die statistischen Momente der Ausgangsgrößen werden näherungsweise aus den Momenten der Eingangsgrößen berechnet. Aus den ermittelten Momenten werden anschließend die Verteilungen der Ausgangsgrößen approximiert.
Die erforderlichen Ersatz-Übertragungsfunktionen werden durch die Berechnung von Stützstellen gewonnen:
| |Modellberechnungen|Modellberechnungen | Verfahren | Verhalten | ohne Interaktion | mit Interaktion | ------------|-------------|------------------|-------------------| First Order | linear | n+1 | 2n²-n+1 | Second Order| quadratisch | 2n+1 | 2n²+1 |
Bedingt durch die kombinatorische Abtastung des Modells steigt die benötigte Anzahl der Modell-Läufe quadratisch mit der Anzahl der Streugrößen n, wenn man Interaktionen zwischen den Streugrößen berücksichtigen muss:
- Im Unterschied zu den Sample-Verfahren ist deshalb das Wissen über existierende Interaktionen sehr wichtig für die Wahl einer optimalen Approximationsfunktion.
- Die Information über Interaktionen zwischen den Streugrößen gewinnt man aus dem Vergleich zwischen Haupt- und Total-Effekten der globalen Sensitivitäten.
Vorteile:
- Das Moment-Verfahren arbeitet sehr genau, wenn das Verhalten der Ausgangsgrößen im Streubereich annähernd lineare oder quadratische Abhängigkeiten zu den Streugrößen aufweist. Die Ergebnisse mit 4 Streugrößen sind dann vergleichbar mit einer Monte-Carlo-Simulation bei einer Stichprobengröße von 100 000.
- Da das Verfahren ohne Zufallszahlen arbeitet, ist es numerisch sehr stabil und erlaubt auch eine schnelle Optimierung unter Berücksichtigung von Streugrößen.
Nachteile:
- Nicht "Fehler-Tolerant":
- Bei der Sample-Methode werden einzelne, abnormal beendete Simulationen in der Stichprobe einfach nicht berücksichtigt.
- Bei der Moment-Methode muss jede Stützstelle korrekt berechnet werden, um die Ersatzfunktion zu generieren. Das stellt sehr hohe Ansprüche an die numerische Stabilität des Simulationsmodells!
- Hoher Rechenaufwand bei einer großen Anzahl von interagierenden Streugrößen.
- Die Teilversagenswahrscheinlichkeiten der einzelnen Restriktionen Fi können mit der Moment-Methode sehr genau berechnet werden, weil die Verteilungsdichten der Restriktionen bekannt sind. Aber die gesamte Systemversagenswahrscheinlichkeit F kann man damit im Unterschied zur Sample-Methode nicht ermitteln! Es wird deshalb eine Hilfsgröße F als Gütekriterium für die Optimierung berechnet, die sich aus den Teilversagenswahrscheinlichkeiten mit den Gewichtsfaktoren wi der einzelnen Restriktionen summiert: