
Grundlagen: Probabilistik: Unterschied zwischen den Versionen
| Zeile 94: | Zeile 94: | ||
# <u>Extrahieren der Maßkette aus dem bemaßtem CAD-Modell</u>[[Datei:Software OptiY-Workflow - Einfache Toleranzkette anordnung.gif|rechts|Maßkette]] | # <u>Extrahieren der Maßkette aus dem bemaßtem CAD-Modell</u>[[Datei:Software OptiY-Workflow - Einfache Toleranzkette anordnung.gif|rechts|Maßkette]] | ||
#:a) Identifizieren des Schlussmaßes M<sub>0</sub> (z.B. Luftspalt) | #:a) Identifizieren des Schlussmaßes M<sub>0</sub> (z.B. Luftspalt) | ||
#:* Alle Maße einer linearen Maßkette | #:* Alle Maße einer linearen Maßkette müssen entlang einer Richtung angeordnet sein! | ||
#:* Das abhängige Maß M<sub>0</sub> der Maßkette ergibt sich aus den gegebenen Maßen M<sub>1</sub>...M<sub>n</sub>. | #:* Das abhängige Maß M<sub>0</sub> der Maßkette ergibt sich aus den gegebenen Maßen M<sub>1</sub>...M<sub>n</sub>. | ||
#:* Das Schlussmaß M<sub>0</sub> wird nur in Prüfzeichnungen bemaßt, aber es existieren Forderungen für die Lage und Größe seines Toleranzbereiches. | #:* Das Schlussmaß M<sub>0</sub> wird nur in Prüfzeichnungen bemaßt, aber es existieren Forderungen für die Lage und Größe seines Toleranzbereiches. | ||
#:* Man legt den Nullpunkt der Maßkette an einen beliebigen Schnittpunkt zwischen zwei Maßen. Außerdem definiert man den positiven Richtungssinn der Maßkette. | #:* Man legt den Nullpunkt der Maßkette an einen beliebigen Schnittpunkt zwischen zwei Maßen. Außerdem definiert man den positiven Richtungssinn der Maßkette. | ||
#:* Ausgehend vom Nullpunkt zeichnet man alle | #:* Ausgehend vom Nullpunkt zeichnet man alle Maß-Vektoren der Maßkette, bis die Kette wieder am Nullpunkt geschlossen wird. | ||
#:* Die Vorzeichenkoeffizienten k<sub>i</sub> ergeben sich entsprechend der Richtung ihres Maß-Vektors zu ±1 (Richtungssinn des Vektors in Bezug auf positiven Richtungssinn der Maßkette). | |||
# <u>Maß-Zerlegung in 3 Komponenten</u> | # <u>Maß-Zerlegung in 3 Komponenten</u> | ||
#:: '''M<sub>i</sub> = N<sub>i</sub> + E<sub>Ci</sub> ± T<sub>i</sub>/2''' | #:: '''M<sub>i</sub> = N<sub>i</sub> + E<sub>Ci</sub> ± T<sub>i</sub>/2''' | ||
Version vom 13. Dezember 2016, 11:18 Uhr
Zielstellung
Experimentell tätige Wissenschaftler unterliegen dem Zwang, ihre Experimente statistisch auszuwerten. Das dafür erforderliche mathematische Rüstzeug kann in dieser kurzen Einführung in die Probabilistik nicht vermittelt werden.
Im Blickfeld dieses Kapitel steht vor allem der Entwicklungsingenieur. Dieser benutzt für seine Berechnungen überwiegend "exakte" Nennwerte. Die Zulässigkeit von Toleranzen ermittelt er danach durch Analyse ihrer Grenzwerte. Damit soll z.B. die Montage oder Funktion auch unter den ungünstigsten Umständen zu 100% sichergestellt werden.
Dem Entwicklungsingenieur ist durchaus bewusst, dass Wahrscheinlichkeiten eine wichtige Rolle beim Auftreten unerwünschter Zustände in seinen Lösungen spielen. Leider sind Menschen (und damit auch Ingenieure) meist sogenannte "Wahrscheinlichkeitsidioten", die das Eintreten bestimmter Ereignisse entweder über- oder unterschätzen (zum "Idiotentest" → Geburtstagsparadoxon).
Der Entwicklungsingenieur hat kaum die Zeit, sich die benötigten mathematischen Methoden tiefgründig anzueignen und sie auf seine Probleme analytisch anzuwenden. Er ist deshalb auf vorhandene Software-Pakete angewiesen, um seine Lösungen einer probabilistischen Analyse zu unterziehen.
Anliegen dieses Kapitels ist die Vermittlung des qualitativen Wissens zu den wahrscheinlichkeitstheoretischen Grundlagen, welche für die qualifizierte Anwendung von Probabilistik-Tools erforderlich ist.
Grundbegriffe
Nennwert
In Anlehnung an den Begriff Nennmaß soll unter Nennwert der geplante Wert für eine physikalisch-technische Größe im weitesten Sinne verstanden werden. Es handelt sich hierbei um einen idealisierten, "exakten Wert", z.B.:
- Physikalische Größe als Produkt aus Maßeinheit und Zahlenwert (Skalar, Vektor, höherstufiger Tensor)
- Geometrisches Element (Punkt, Kurve, Fläche, Körper)
- Funktionale Abhängigkeit (Kennlinie, Kennfeld, Übertragungsfunktion)
Die idealisierten Nennwerte bilden die Grundlage bei der Entwicklung optimaler Lösung für technische Aufgabenstellungen. Dafür gibt es plausible Gründe:
- Physikalische Effekte außerhalb der Quantenmechanik werden mathematisch als Verknüpfung zwischen den aktuellen Istwerten der beteiligten physikalischen Größen beschrieben (Klassische Physik).
- Praktisch sämtliche CAE-Systeme arbeiten mit deterministischen Modellen (basieren auf Effekten der klassischen Physik und euklidischen Geometrie).
- Deterministische Modelle erzeugen aus "exakten" Eingangsgrößen mittels eindeutiger Übertragungsfunktionen "exakte" Ausgangsgrößen:

Toleranz
Ein exakter Nennwert ist praktisch nie realisierbar. Deshalb muss für jeden Nennwert ein Wertebereich (Toleranzfeld) definiert werden, dessen Einhaltung garantiert, dass die Funktionalität der Lösung gewährleistet ist. Diesen zulässigen Wertebereich bezeichnet man auch kurz als Toleranz. Im Spezialfall (z.B. Press-Passungen) liegt der Nennwert außerhalb des Toleranzfeldes.
Man unterscheidet wie bei den "Nennwerten" unterschiedliche Toleranz-Typen:
- Maßtoleranzen, Bauteil-Toleranzen (z.B. Kennwerte von einfachen elektronischen oder mechanischen Bauelementen)
- Form- und Lagetoleranzen sowie Oberflächenangaben
- Funktionale Toleranzen (Material-Kennlinien, Wandler-Kennfelder, Übertragungsfunktionen)
Handelt es sich um deterministische Modelle mit linearem Übertragungsverhalten, so können durch die Berechnung aller möglichen Kombinationen der Toleranzgrenzen von Xi die Minima/Maxima aller Yj bestimmt werden:

- Ein Beispiel für ein lineares Modell ist die einfache Toleranzkette im OptiYummy-Tutorial.
- Für nichtlineare Modelle gilt nicht das Superpositionsprinzip. Deshalb führt die kombinatorische Form der Toleranzanalyse für nichtlineare Probleme nicht mit Sicherheit zu den Extremwerten der Output-Größen Yj.
Grundbegriffe nach DIN ISO 286 für Maßtoleranzen:

Diese Begriffe kann man sinngemäß z.B. auch auf funktionelle Toleranzen anwenden, indem man darin "maß" durch "wert" ersetzt.
Streuungen
Toleranzangaben beziehen sich nur auf die zulässigen Grenzwerte für einen Nennwert. Die tatsächlich auftretenden Istwerte treten je nach Herkunft (z.B. Fertigungsverfahren, Umweltbedingungen, Alterung) innerhalb dieser Grenzwerte mit unterschiedlichen Verteilungsfunktionen auf. In Erweiterung des Toleranz-Begriffes wird für die statistische Analyse von Ausfallwahrscheinlichkeiten der Begriff der "Streuung" benutzt.
Eine Streuung ist definiert durch
- die Toleranz (d.h. die Grenzwerte des Toleranzfeldes) und
- die Verteilungsdichte-Funktion innerhalb des Toleranzfeldes (z.B. Gleich- oder Normalverteilung).
Eine Streuung enthält die Menge aller Werte für die zugehörige streuende Größe:
- deterministische Modelle können jeweils nur ein einzelnes Exemplar (= ein Parametersatz) aus der gesamten Input-Streuung berechnen,
- probabilistische Modelle sind erforderlich, um entsprechend der Verteilungsdichtefunktionen der Input-Streuungen das Verhalten aller möglichen Exemplare zu berechnen (Output-Streuungen):

Probabilistik
Probabilistik (auch als Wahrscheinlichkeitstheorie bezeichnet) ist aus der Untersuchung von Zufallsgeschehen hervorgegangen:
- Die Wahrscheinlichkeitstheorie formalisiert die Modellierung und Simulation von Zufallsereignissen.
- Gemeinsam mit der Statistik, die anhand von Beobachtungen zufälliger Vorgänge Aussagen über das zugrunde liegende Modell trifft, bildet sie das mathematische Teilgebiet der Stochastik.
- Die Stochastik als Lehre von der Häufigkeit und Wahrscheinlichkeit ("Kunst des Vermutens") beschäftigt sich mit der Definition, Durchführung und Auswertung von Zufallsexperimenten.
Zumindest für den Ingenieur ist die Begriffsvielfalt zu den unterschiedlichen Aspekten der Stochastik verwirrend. Folgt man zu diesen Begriffen z.B. den Verlinkungen in der Wikipedia, so gewinnt man leider den Eindruck, dass viele unscharfe Überschneidungen und Querbezüge zwischen diesen Aspekten existieren. Deshalb wird hier eine pragmatische Sicht auf die Entwicklung, Simulation und Analyse probabilistischer Modelle vertreten:
- Es wird bei der Berücksichtigung von Streuungen im Entwicklungsprozess durchgängig der Begriff "Probabilistik" verwendet, obwohl "Stochastik" zutreffender wäre.
- Der Begriff "Stochastik" besitzt ein negatives Image im Sinne von Chaos, Unordnung und Zufall und sollte deshalb im Zusammenhang mit der Entwicklung hochwertiger Produkte vermieden werden.
- Der Begriff "Probabilistik" impliziert dagegen sorgfältiges Arbeiten durch die Berücksichtigung von Wahrscheinlichkeiten (d.h. aller Eventualitäten) im Entwicklungsprozess.
Klassische Maximum-Minimum-Methode
Mit der Maximum-Minimum-Methode können analytisch für die abhängigen physikalischen Größen (z.B. Schlussmaß einer Toleranzkette) die Lage und Größe der Toleranzen unter Berücksichtigung der ungünstigsten Kombination der Istwerte aller unabhängigen physikalischen Größen berechnet werden (Worst Case). Diese Methode garantiert die vollständige Austauschbarkeit aller Komponenten, solange diese sich an die vorgegebene Toleranz-Spezifikation halten.
Grundlage der Maximum-Minimum-Methode für Maßketten ist in Analogie zum Fehlerfortpflanzungsgesetz das arithmetisches Toleranzfortpflanzungsgesetz:
- [math]\displaystyle{ T_0=\sum_{i=1}^m \left| \frac{\partial f}{\partial M_i} \right| \cdot T_i }[/math]
Mi : unabhängiges Einzelmaß Ti : unabhängige Einzeltoleranz T0 : Toleranz des Schlussmaßes M0 ƒ : Abhängigkeit M0 = ƒ ( M1 ... Mm )
Daraus resultiert für den Spezialfall linearer Maßketten der Vorzeichenkoeffizient ki zu:
- [math]\displaystyle{ k_i=\frac{\partial f}{\partial M_i}=±1 }[/math]
Deshalb kann man lineare Maßketten auch manuell noch relativ einfach berechnen. Der allgemeine Fall nichtlinearer Maßketten ist auf Grund der vielen partiellen Ableitungen der nichtlinearen Funktion ƒ sehr aufwändig und fehleranfällig bei der manuellen Handhabung!
Vorgehen bei der Maximum-Minimum-Methode für lineare Maßketten:
- Extrahieren der Maßkette aus dem bemaßtem CAD-Modell
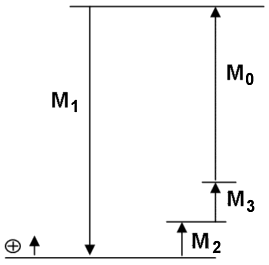
Maßkette - a) Identifizieren des Schlussmaßes M0 (z.B. Luftspalt)
- Alle Maße einer linearen Maßkette müssen entlang einer Richtung angeordnet sein!
- Das abhängige Maß M0 der Maßkette ergibt sich aus den gegebenen Maßen M1...Mn.
- Das Schlussmaß M0 wird nur in Prüfzeichnungen bemaßt, aber es existieren Forderungen für die Lage und Größe seines Toleranzbereiches.
- Man legt den Nullpunkt der Maßkette an einen beliebigen Schnittpunkt zwischen zwei Maßen. Außerdem definiert man den positiven Richtungssinn der Maßkette.
- Ausgehend vom Nullpunkt zeichnet man alle Maß-Vektoren der Maßkette, bis die Kette wieder am Nullpunkt geschlossen wird.
- Die Vorzeichenkoeffizienten ki ergeben sich entsprechend der Richtung ihres Maß-Vektors zu ±1 (Richtungssinn des Vektors in Bezug auf positiven Richtungssinn der Maßkette).
- a) Identifizieren des Schlussmaßes M0 (z.B. Luftspalt)
- Maß-Zerlegung in 3 Komponenten
- Mi = Ni + ECi ± Ti/2
- Diese 3 Komponenten werden in der Berechnung unabhängig voneinander betrachtet.
- Ni .... Nennwert
- Ti .... Toleranz
- NCi ... Toleranzmittenabmaß

Probabilistische Simulation
Notwendigkeit und Randbedingungen
Die Eigenschaften technischer Systeme streuen in der Realität. Sie sind durch ihr Nennverhalten und eine stochastische Verteilung um dieses Nennverhalten gekennzeichnet:
- Ursachen für die stochastische Verteilung der Systemeigenschaften sind z.B. Umwelteinflüsse, Fertigungsungenauigkeiten, Prozessunsicherheiten, Alterung und Verschleiß.
- Diese realen Aspekte der Unsicherheit müssen bei der Beurteilung und bei der Auslegung technischer Systeme beachtet werden.
- Mit deterministischer Simulation kann man das vollständige Systemverhalten nicht vorhersagen.
- Erforderlich ist eine probabilistische Simulation. Aus den Streuungen der Eingangsgrößen werden dabei die Streuungen der Ausgangsgrößen berechnet.
Zur Simulation technischer Systeme, welche mit den Effekten der klassischen Physik modellierbar sind, entstehen im Entwurfsprozess ausschließlich deterministische Modelle:
- Im Sinne der Effektivität sollten bereits entwickelte deterministische Modelle mit möglichst geringen Mehraufwand für die probabilistische Simulation nutzbar gemacht werden.
- Die Berechnung der theoretisch unendlich vielen Parameter-Varianten eines Systems (z.B. durch "Erwürfeln" mit Monte-Carlo-Methoden) ist wegen des zeitlichen Aufwandes praktisch nicht möglich.
- Die probabilistische Simulation auf Basis deterministischer Modelle kann nur durch die Berechnung geeigneter, repräsentativer Stichproben erfolgen.
Stochastische Verteilungen der Modellparameter
Unabhängig vom Verfahren der probabilistischen Simulation müssen die Streuungen der Inputgrößen entsprechend der realen Bedingungen definiert werden. Hier werden im Weiteren nur stetige Verteilungen mit unendlich vielen möglichen Zuständen innerhalb der Toleranzgrenzen betrachtet:
- Im Beispiel ist die Verteilungsfunktion der Normalverteilung dargestellt. Die Toleranz T ist verknüpft mit der Standardabweichung über T = 6·σ:

Es existieren sehr viele spezielle Verteilungsfunktionen für die Beschreibung von Streuungen. Für die Beschreibung der streuenden Modellparameter von probabilistischen Modellen genügen im Sinne der Einfachheit und Allgemeingültig im Prinzip drei Formen stochastischer Verteilungen:
- Normalverteilung:
- Verteilungen, die durch Überlagerung einer großen Zahl von unabhängigen Einflüssen entstehen, sind annähernd normalverteilt.
- Die Abweichungen der (Mess)Werte vieler natur-, wirtschafts- und ingenieurswissenschaftlicher Vorgänge vom Mittelwert lassen sich deshalb durch die Normalverteilung in sehr guter Näherung beschreiben.
- Die Toleranzen der Technik bezeichnen das Intervall der Abweichung ±3σ vom Mittelwert und enthalten damit 99,73% aller möglichen Werte:
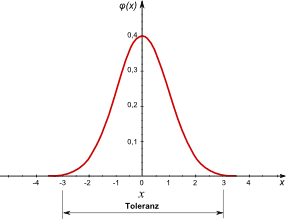
- Wichtig: Das bedeutet, dass ca. 0,3% aller Istwerte einer normalverteilten Streuung außerhalb der Toleranzgrenzen liegen!
- Gleichverteilung:
- Der Grundgedanke einer Gleichverteilung ist, dass es keine Präferenz gibt. Alle möglichen Istwerte sind innerhalb des Toleranzgrenzen gleich wahrscheinlich (Verteilungsdichte=konstant). Außerhalb der Toleranzgrenzen ist die Verteilungsdichte=0:
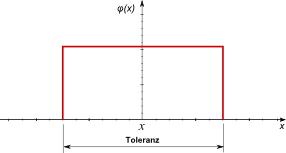
- Wenn man die Qualität der Verteilungsdichtefunktion nicht kennt, so sollte man nach dem Indifferenzprinzip von Laplace eine Gleichverteilung annehmen.
- Dies betrifft z.B. Bereiche zulässiger Umgebungsbedingungen (z.B. wie Temperaur, Feuchte, Kräfte), falls man keine statistischen Informationen zu diesen besitzt.
- Der Grundgedanke einer Gleichverteilung ist, dass es keine Präferenz gibt. Alle möglichen Istwerte sind innerhalb des Toleranzgrenzen gleich wahrscheinlich (Verteilungsdichte=konstant). Außerhalb der Toleranzgrenzen ist die Verteilungsdichte=0:
- Statistische Kennzahlen (z.B. unter Nutzung der allgemeinen Lambda-Verteilung):
- Besitzt man statistische Daten für eine Streuung, so kann der konkrete Verlauf der zugehörigen Verteilung durch die Momente der Verteilung in guter Näherung beschrieben werden:
- Diese Kennzahlen (Momente) können aus den statistischen Daten ermittelt werden.
- Die Parameter der allgemeinen Lambda-Verteilung (Lambda1 ... Lambda4) werden anschließend durch Parameter-Identifikation automatisiert ermittelt:
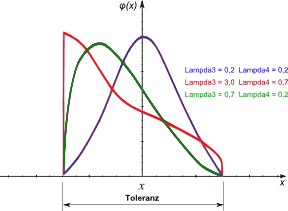
- Durch diese Parameter kann eine beliebige Verteilungsfunktion abgebildet werden. Dabei ist Lambda1 der Erwartungswert X und Lambda2 die Skalierung der Verteilung infolge der Toleranz T=2/Lambda2. Lamda3 und Lambda4 sind die Formfaktoren.
- Bei symmetrischer Verteilung ergibt sich Lambda3=Lambda4. Umtauschen von Lambda3 und Lambda4 bedeutet eine Spiegelung der Verteilung um den Mittelpunkt.
- Hinweis:
- Trotz normalverteilter Fertigungstoleranzen können in der Realität infolge der Qualitätskontrolle keine Maße außerhalb der Toleranzgrenzen vorkommen.
- Bei Verwendung der allgemeinen Lampda-Verteilung liegen alle möglichen Istwerte innerhalb der Toleranzgrenzen.
- Es ist deshalb meist sinnvoll, die Normalverteilung von Maßtoleranzen als Lampda-Verteilung zu parametrisieren.



Statistische Versuchsplanung (Design of Experiments DoE)
Im Folgenden werden nur probabilistische Simulationen auf der Grundlage deterministischer Modelle betrachtet:
- Die Übertragungsfunktion zwischen allen Input- und Outputgrößen ist durch ein deterministisches Modell vollständig definiert.
- Es ist jedoch meist unmöglich, uneffektiv oder zu ungenau, statistische Zusammenhänge zwischen Input- und Outputgrößen direkt mit dem deterministischen Modell durch hinreichend große Stichproben-Rechnungen zu ermitteln. Die Berechnungszeit für eine Modellberechnung ist dafür meist zu groß.
- Zugeschnitten auf die konkreten Ziele einer probabilistischen Simulation müssen deshalb geeignete Ersatzmodelle gebildet werden. Diese dienen dann anstatt der originalen Modelle zur Analyse der statistischen Zusammenhänge zwischen den relevanten Input- und Outputgrößen.
Statistische Versuchsplanung ermöglicht mit möglichst wenigen deterministischen Simulationen (= minimaler "realer" Stichprobenumfang) den Wirkzusammenhang zwischen Einflussfaktoren (= unabhängige Inputgrößen) und Zielgrößen (= abhängige Outputgrößen) hinreichend genau zu ermitteln:
- Der erforderliche Umfang einer Stichprobe für das Erreichen einer gewünschten Ergebnis-Genauigkeit ist stark abhängig vom Vorwissen über die Eigenschaften des zu untersuchenden Systems (hier des deterministischen Modells).
- Besitzt das zu untersuchende System eine stetige und nur leicht gekrümmte Übertragungsfunktion, so genügt ein relativ grobes Abtastraster im Streubereich der Input-Größen.
- Je unstetiger und welliger die Übertragungsfunktion ist, desto enger muss die zu generierende Stichprobe den Streubereich abtasten.
Ersatzmodelle (Antwortflaechen)
Für sehr schnell rechnende Modelle (<1s) wäre es möglich, eine "erwürfelte" Stichprobe (Monte-Carlo-Verfahren) direkt statistisch auszuwerten. Allerdings führen selbst einige 1000 Modellrechnungen hierbei noch zu unerwünscht hohen statistischen Fehlern.
In der Praxis lässt man den statistischen Fehler gegen Null konvergieren, indem man riesige Stichproben (z.B. 1000000) anhand eines extrem schnellen Ersatzmodells berechnet. Der verbleibende Fehler der probabilistischen Simulation resultiert nur aus einer unzureichenden Abbildung der originalen Übertragungsfunktion auf das Ersatzmodell.
Für die probabilistische Simulation muss nur ein kleiner Teil der Übertragungsfunktion des Originalmodells auf das Ersatzmodells abgebildet werden:

- Inputgrößen: für die eine Streuung definiert ist
- Outputrößen: die für statistische Analyse benötigt werden (Gütekriterien, Restriktionen)
- Parameter-Raum: welcher durch die Toleranzen der streuenden Inputgrößen aufgespannt wird.
Für jede berücksichtigte Outputgröße Yi wird eine sogenannte Antwortfläche Yi=f(X1...Xm) mittels einer günstigen Ansatzfunktion f approximiert:
- Die approximierten Ersatzfunktionen jeder Outputgröße stellen praktisch Flächen im n-Dimensionalen Parameterraum dar.
- Anhand dieser Ersatzfunktionen wird die Systemantwort auf die eingespeisten Parameterwerte berechnet.
- Daraus resultiert die Bezeichnung Response Surface Method (RSM).
Approximation mit Polynom-Ansatz
Grundlage der praktisch verwendeten Ansatzfunktionen sind Polynomfunktionen n. Ordnung (n≥0) und Potenzreihen (z.B. in Form der Taylorreihe):
- Durch Wahl einer hinreichend großen Polynom-Ordnung n soll eine möglichst gute Nachbildung der Krümmungen des Originalmodells erreicht werden.
- Die minimal erforderliche Anzahl der Modellberechnungen M (=Stichprobengröße) ergibt sich aus der Anzahl p der stochastischen Variablen und der gewählten Ordnung n der Polynom-Funktion zu M=(p²-p)/2+n*p+1
- Die Koeffizienten der Ansatzfunktionen werden mittels der Methode der kleinsten Quadrate so berechnet, dass die mit dem Originalmodell berechneten Stützstellen (reale Stichprobe) möglichst nah an den resultierenden Antwortflächen liegen. Das Beispiel sieht man für einen E-Magneten die Kraft F = f(Strom i, Luftspalt s):
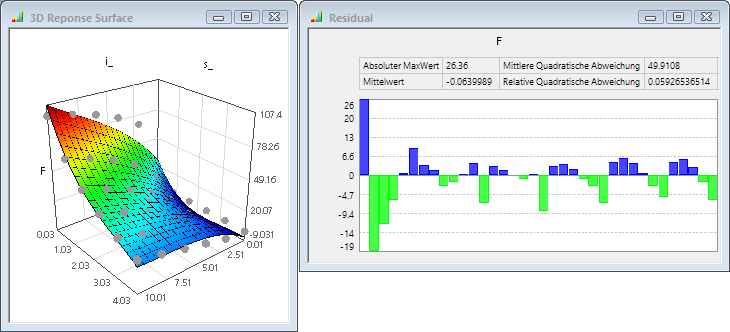
- Die Residuen der Ausgleichsrechnung für eine vorliegende Stichprobe zeigen nur, wie genau die Ausgleichsfläche in die vorhandene Punktwolke passt (Abstände aller Einzelpunkte vom Ersatzmodell).
- Informationen zur Genauigkeit der Ausgleichsfläche in den Zwischenräumen der Punktwolke sind mit dem Polynom-Ansatz nicht zu gewinnen.

Approximation mit Gauß-Prozess
Der sogenannte Gauß-Prozess bringt eine neue Qualität im Vergleich zur Polynom-Approximation, indem alle vorhandenen Punkte „exakt“ in den Funktionsverlauf eingebunden werden:

Der Gauß-Prozess, angewandt in der Geostatistik auch als Kriging bekannt, ist ein statistisches Verfahren, mit dem man Werte an Orten, für die keine Probe vorliegt, durch umliegende Messwerte interpolieren oder auch annähern kann.
Der Gauß-Prozess besteht aus einem globalen Modell f(x) und einem stochastischen Prozess Z(x), welcher die mögliche Abweichung von dem globalen Modell beschreibt:

- x ist ein m-dimensionaler Parametervektor.
- Y(x) ist der Ergebnisvektor für den Punkt x im Parameterraum.
- f(x) sind Polynome beliebiger Ordnung, welche zusammen mit den unbekannten Regressionskoeffizienten βi die Regressionsfunktion bilden.
- Z(x) ist ein stationärer stochastischer Prozess mit dem Mittelwert Null, der Varianz σ und der Covarianz R. Dieser Anteil des Gauß-Prozesses beschreibt das 95% Erwartungsintervall für jeden Punkt x des Parameterraumes.
In dem englischen Wikipedia-Artikel zum Kriging wird das für die Interpolation einer eindimensionalen Funktion sehr anschaulich dargestellt:

Die berechneten Grenzverläufe des Erwartungsintervalls werden wesentlich bestimmt durch das Erfahrungswissen in Hinblick auf den erwartenden Verlauf der zu interpolierenden Funktion zwischen den bekannten Werten der Stichproben-Exemplare. Diese Erwartung wird durch die Wahl einer geeigneten Covarianz-Funktion R beschrieben.
- Im Folgenden werden beispielhaft unterschiedliche Covarianz-Funktionen R aufgelistet. Diese beschreiben den Verlauf des 95% Erwartungsintervalls zwischen den Stützstellen in Abhängigkeit von der Stützstellendichte. Die folgende Notation bezieht sich auf zwei Stützstellen x1 und x2 im Abstand (x1−x2):
- Square Exponential
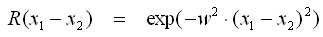
- Exponential
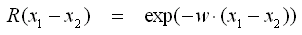
- Gamma-Exponential
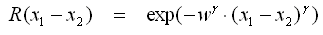
- Matern Class 3/2
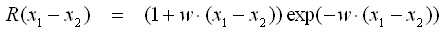
- Matern Class 5/2
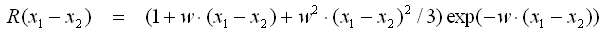
- Rational Quadratic
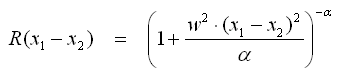

- Der allgemeine Fall für Exponential-Funktionen ist Gamma-Exponential, die anderen beiden Exponentialfunktionen sind die Spezialfälle für γ=1 bzw. γ=2.
- Die Matern Class Funktionen sind Erweiterungen der Exponential-Funktion.
- Die Hyper-Parameter w, γ and α werden mittels der Maximierung der Likelihood-Funktion der multivariaten Normalverteilung ermittelt.
Über die Polynomordnung des globalen Modells f(x) kann man einen Kompromiss finden zwischen bester Anpassung der interpolierten Regressionsfunktion an vorhandene Stützstellen und optimalem Verlauf zwischen diesen Stützstellen:
- Die Polynomordnung des globalen Modells f(x) bestimmt die allgemeine Richtung (globale Anpassung) der Regressionsfunktion. Die dabei verbleibenden Residuen sind noch sehr groß.
- Wenn man die globale Anpassung mit einer zu hohen Ordnungen der Polynome durchführt, besitzt die Kurve mehr Freiheitsgrade als nötig. Das führt dann zu Welligkeiten zwischen den Stützstellen, weil dies durch keine Zwangsbedingungen verhindert wird.
- Der stochastische Prozess Z(x) hat die Aufgabe, die verbleibenden Residuen mittels der Covarianz-Funktion (Normal-Verteilung) zu eliminieren (lokale Anpassung).
- Wenn die Anzahl der Stützstellen bzw. der Daten hinreichend groß ist und man die verbleibenden Residuen statistisch auswertet, entsteht eine Normal-Verteilung (auch Gauss-Verteilung genannt) mit dem Mittelwert=0. Das ist die ursprüngliche Idee des Gauß-Prozesses.
Der Gauß-Prozess ermöglicht es, ausgehend von einer vorhandenen Stichprobe mit möglichst wenigen zusätzlichen Stützstellen ein hochwertiges Ersatzmodell zu gewinnen (= adaptiver Gauß-Prozess). Dabei werden ausgehend von den vorhandenen Abtastpunkten nach Identifikation der Antwortflächen die Positionen der maximalen Unsicherheit und der maximal zu erwartenden Verbesserung ermittelt. Dort werden mit dem Modell zwei neue Stützstellen berechnet:

Dieser Prozess wird iterativ ausgeführt (bis max. Stützstellen-Zahl oder Genauigkeit erreicht):

Wichtig:
- Man sollte nie vergessen, dass ein Originalmodell auch nur ein fehlerbehafteter Ersatz für das eigentlich zu untersuchende Original darstellt.
- Modellbasierte statistische Aussagen im Promille-Bereich sind in Bezug auf das Original immer sehr skeptisch zu betrachten!
- Die Response Surface Methode erzeugt hier eine weitere Modell-Hierarchie im Experimentierprozess.
Verfahren der statistischen Versuchsplanung
- Die unabhängigen Variablen (Input- bzw. Einflussgrößen) des zu untersuchenden Systems heißen in der statistischen Versuchsplanung Faktoren oder auch Design Variablen.
- Bei der statistischen Versuchsplanung werden immer mehrere Faktoren "gleichzeitig" verändert ("gleichzeitig" im Sinne der Wirkung auf das System).
- Es existieren verschiedene Algorithmen, um die Wirkung der Faktoren auf das Systemverhalten anhand diskreter Messungen oder Berechnungen (Abtast-Schritte) zu ermitteln.
- Die grundsätzlichen Verfahren der statistischen Versuchsplanung werden im Folgenden kurz erläutert.
Sampling-Verfahren (Monte Carlo)
Es handelt sich hierbei um eine stochastische Simulation mit Zufallszahlen. Mit diesem Verfahren wird die Generierung einer Zufallsstichprobe sehr gut nachgebildet:
- Die Streuungen der Inputgrößen lassen sich mit Hilfe von Zufallszahlen abbilden.
- Die einzelnen Ist-Werte Mai verteilen sich zufällig im jeweiligen Toleranzbereich Ti , so dass man sie durch die Summe aus dem Nennwert Mni und der Zufallsvariablen Zi ersetzen kann:
- Die Zufallsvariable Zi beschreibt die charakteristische Häufigkeitsverteilung innerhalb des zugehörigen Toleranzbereiches Ti.
- Das Beispiel zeigt für einen Elektro-Magneten die Histogramme mit den Häufigkeitsverteilung der Streuungen der Luftspalte als Input-Größen und den daraus resultierenden Streuungen der Magnet-Kraft F und des Koppelflusses Psi als Output-Größen:
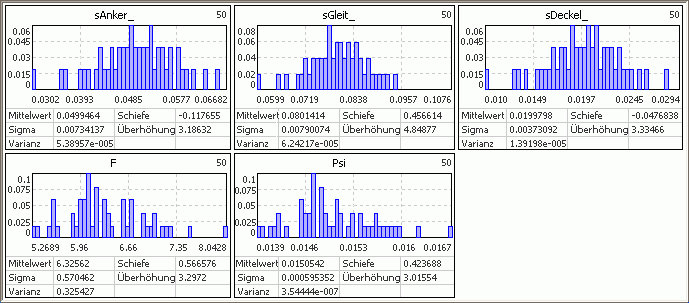
- Die Streuungen der Luftspalte sollen eine Normalverteilung aufweisen. Dies wird mit der relativ kleinen Stichprobengröße=50 nur sehr grob nachgebildet.
- Deshalb ist es üblich, eine mittels Sampling-Verfahren mit dem Original-System gewonnene Stichprobe nicht direkt statistisch auszuwerten, sondern nur zur Gewinnung hinreichend genauer Ersatzmodelle für jede Output-Größe zu benutzen.
- Auf diese Ersatzmodelle wird dann erneut das Sampling-Verfahren angewandt, auf Grund der kurzen Rechenzeiten jedoch mit Stichprobengrößen=105...106. Damit ergeben sich sehr genaue Verläufe für alle Verteilungsdichten und der statistische Fehler für die berechneten statistischen Momente der Output-Größen tendiert gegen Null.
- Der Fehler der Response Surface Method (RSM) bei Anwendung eines Sample-Verfahrens resultiert aus der Ungenauigkeit bei der Approximation der Ersatzmodelle.

Neben ungeeigneten Funktionsansätzen für die Ersatzmodelle ist eine Fehlerquelle eine ungünstige Verteilung der generierten Zufallswerte für die Input-Größen bei geringem Stichprobenumfang. Deshalb wurden Sample-Methoden entwickelt, welche eine gleichmäßigere Ausfüllung der Input-Streuungen auch bei geringem Stichprobenumfang gewährleisten:
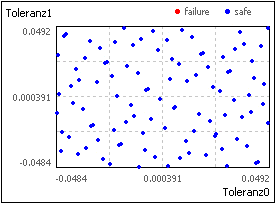
- Latin Hypercube Sampling:
- Bei der klassischen Monte-Carlo-Methode werden die Zahlen entsprechend ihrer Verteilung direkt vom Zufallsgenerator erzeugt. Bei dem Verfahren Latin Hypercube wird zuvor die Verteilungsfunktion in eine Anzahl gleich breiter Intervalle unterteilt. Für jedes dieser Intervalle wird dann entsprechend der Verteilungsfunktion eine Menge von Zahlen vom Zufallsgenerator erzeugt. Die im vorherigen Bild gezeigte Stichprobe wurde mit diesem Verfahren generiert. Nur dadurch entstanden Input-Streuungen, welche trotz der kleinen Stichprobe bereits einer Normalverteilung ähneln.
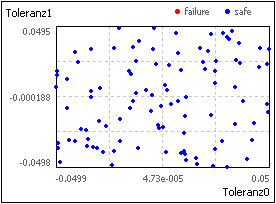
- Sobol Sampling:
- Das Verfahren nutzt im Unterschied zur "reinen" Monte-Carlo-Simulation (1. Bild) eine Quasi-Zufallszahlen-Sequenz (2. Bild).
- Durch Ausnutzung von Symmetriebeziehungen erfolgt eine gleichmäßigere Verteilung der Punktwolke im Parameterraum.
- Damit benötigt das Verfahren für die gleiche Genauigkeit nur ca. 1/10 der Stichprobengröße:


Full Factorial Design

Dieses Verfahren stellt praktisch eine Rastersuche im betrachteten Bereich der Streuungen dar. Jede Input-Variable wird in diskrete Punkte oder Stufen gleichmäßig aufgeteilt. Für sämtliche Kombinationen aus den Input-Variablen und ihren Stufen werden die Werte der Output-Größen ermittelt. Die Anzahl der Modellberechnungen steigt exponentiell mit der Anzahl der Stufen. Für n Input-Variablen mit k Stufen werden kn Modellberechnungen benötigt. Im Beispiel sieht man die Stützstellen für 3 Input-Variablen mit 3 Stufen.
Ein solches Experiment ermöglicht es, die Wirkung der einzelnen Faktoren auf die Output-Größen sowie die Effekte der Wechselwirkung zwischen den Faktoren auf die Output-Größen zu untersuchen. In der Praxis scheitert die direkte Anwendung dieser Methode an der zeitlich nicht mehr zu realisierenden hohen Anzahl von Stützstellen bei einer feineren Stufung mehrerer Input-Größen. In solchen Fällen bildet man Ersatzmodelle auf Grundlage einer gröberen Stufung und führt die statistischen Berechnungen mit feiner Stufung anhand dieser Ersatzmodelle durch.
Central Composite Design

Das Central Composite Design CCD setzt sich aus einem 2n faktoriellem Design und 2n des so genannten Star Point Design zusammen. Außerdem muss der Zentrumspunkt berechnet werden. Für n Input-Variablen benötigt man somit 2n +2n + 1 Modellberechnungen. Das CCD dient als Grundlage zur Generierung von Ersatzmodellen 2. Ordnung für die Output-Größen. Dabei werden mit dem CCD für drei oder mehr Input-Variablen weniger Versuche benötigt, als im Vergleich zu einem 3n faktoriellen Design. Im Beispiel ist eine schematische Darstellung des CCD für drei Input-Variablen abgebildet.
Moment-Verfahren
Bei der Moment-Methode handelt sich um ein analytisches Verfahren. Für jede betrachtete Output-Größe eines Modells wird eine Funktion f gebildet, mit welcher sich der Wert der Output-Größe aus dem Variablenvektor x der n Streugrößen berechnen lässt:
- Für die Approximation jeder dieser Funktionen f wird eine Taylor-Reihe erster bzw. zweiter Ordnung benutzt (Glied 2. Ordnung gelb):
- Wenn Interaktionen zwischen Eingangsgrößen existieren, werden sie paarweise berücksichtigt. Die Ersatzfunktion f wird dafür um ein Glied mit linearen Kreuzableitungen (grün) ergänzt.
- Die Taylorreihen werden durch die Berechnung von Stützstellen gewonnen. Abtastungen erfolgen nur mit Grenz- und Mittenwerten der Input-Streuungen Si (im Beispiel für 3 Input-Streuungen):




| |Modellberechnungen|Modellberechnungen | Verfahren | Verhalten | ohne Interaktion | mit Interaktion | ------------|-------------|------------------|-------------------| First Order | linear | n+1 | 2n²-n+1 | Second Order| quadratisch | 2n+1 | 2n²+1 |
- Die statistischen Momente der Output-Größen werden auf Grundlage der Taylorreihen analytisch aus den Momenten der Input-Größen berechnet. Aus den ermittelten Momenten werden anschließend die Verteilungen der Output-Größen approximiert.
- Da das Verfahren ohne Zufallszahlen arbeitet, ist es numerisch sehr stabil und erlaubt auch eine schnelle Optimierung unter Berücksichtigung von Streugrößen.