Software: SimX - Nadelantrieb - Probabilistik - Sample-Methoden
"Sample" ist der englische, auch im Deutschen gebrauchte Begriff für eine Stichprobe. Bei den Sampling-Verfahren der probabilistischen Simulation handelt es sich um stochastische Simulationen mit Zufallszahlen.
Jedes Modell-Exemplar innerhalb der zu simulierenden Stichprobe erhält einen eigenen Parameter-Satz. Die Parameter jedes Modell-Exemplars werden aus den aktuellen Nennwerten (Toleranzmittenwert) und einer "erwürfelten" Abweichung vom Mittenwert entsprechend der zugeordneten Verteilungsdichte-Funktionen ermittelt. Die Anzahl der zu simulierenden Modell-Exemplare entspricht dem Stichprobenumfang. Aus allen Simulationsläufen erhält man die Gesamtverteilung der Ausgangsgrößen (Restriktionen und Gütekriterien).
Dadurch kann man sich eine aufwändige und problemabhängige Herleitung der partiellen Ableitungen z.B. einer komplexen Toleranzkette ersparen. Mit der Sample-Methoden kann man beliebige Toleranzverteilung simulieren. Die Genauigkeit des Verfahrens hängt entscheidend von der Anzahl der Modelldurchrechnungen (Stichprobenumfang) ab, die leider exponentiell zu der Anzahl der Toleranzen steigen muss. Diese Methode ist mit einem hohen Rechenaufwand verbunden, jedoch universell einsetzbar.
In OptiY sind mehrere unterschiedliche Verfahren implementiert. Diese unterscheiden sich vor allem dadurch, wie "intelligent" die Exemplare innerhalb einer Stichprobe "erwürfelt" werden.
Monte Carlo Sampling

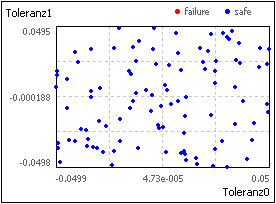
- Bei der Monte-Carlo-Simulation wird über die gesamte Toleranzbreite mit "echten" Zufallszahlen "gewürfelt".
- Der erforderliche Stichprobenumfang N für eine angestrebte "saubere" Verteilungsfunktion der Toleranzgrößen ist deshalb relativ hoch!
- Erst bei einer Stichprobengröße von ca. N=1 000 000 konvergiert der Fehler dieser Toleranzsimulation gegen Null!
- Bei N=50 wird eine Normalverteilung z.B. nur ungenau nachgebildet (Bild rechts).
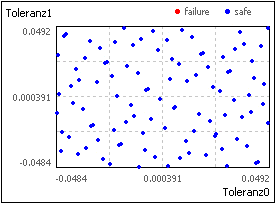
Latin Hypercube Sampling
- Im Unterschied zum klassischen "Monte Carlo Sampling" wird beim Latin Hypercube Sampling die gesamte Toleranzbreite eines streuenden Parameters in Teilintervalle zerlegt.
- Jedes Teilintervall wird je nach vorgegebener Verteilungsfunktion mit Zufallszahlen gefüllt.
- Deshalb wird eine "saubere" Verteilungsfunktion mit relativ kleinem Stichprobenumfang erreicht (Beispiel Normalverteilung N=50):

Sobol Sampling
- Das Verfahren nutzt im Unterschied zur "reinen" Monte-Carlo-Simulation (1. Bild) eine Quasi-Zufallszahlen-Sequenz (2. Bild).
- Durch Ausnutzung von Symmetriebeziehungen erfolgt eine gleichmäßigere Verteilung der Punktwolke im Parameterraum.
- Damit benötigt das Verfahren für die gleiche Genauigkeit nur ca. 1/10 der Stichprobengröße:


Response Surface Methode (Virtuelle Stichprobe)
Als direktes Ergebnis der Stichproben-Simulation mittels Sampling-Methode liegt eine Punktwolke vor, welche die Verknüpfung zwischen den streuenden Entwurfsparametern und den Ergebnisgrößen (Gütekriterien, Restriktionen) repräsentiert:
- Geht man davon aus, dass zwischen den Parametern und Ergebnisgrößen ein stetiger funktioneller Zusammenhang besteht, so kann man diesen durch eine Approximationsfunktion abbilden.
- Im OptiY werden drei Verfahren für die Approximation bereitgestellt: Polynomial, Gauss Prozess und Adaptiver Gauss Prozess.
- Wir nutzen in dieser Übung die standardmäßig eingestellte Polynomiale Approximation. Damit können Polynome beliebiger Ordnung als Approximationsfunktion für jede Ergebnisgröße verwendet werden:
- [math]\displaystyle{ P(x) = \sum_{i=0}^n a_ix^i = a_nx^n + a_{n-1}x^{n-1} + \cdots + a_2x^2 + a_1x + a_0 }[/math]
- Durch Anwendung der Methode der kleinsten Fehlerquadrate werden die Parameter der Polynome so bestimmt, dass die Approximationsfunktionen möglichst gut in die Punktwolke der "gesampelten" Stichprobe passen.
- Die minimal erforderliche Anzahl der Modellberechnungen M (=Stichprobengröße) ergibt sich aus der Anzahl n der stochastischen Variablen und der gewählten Ordnung O der Polynom-Funktion zu M=(n²-n)/2+O*n+1
Die mittels dieser Ausgleichsrechnung ermittelten Ersatzfunktionen (ein Polynom pro Ergebnisgröße), kann man in der statistischen Auswertung als Grundlage für eine "virtuelle Stichprobe" benutzen. Man spricht auch von der "Response Surface Methode" (RSM), weil die Ersatzfunktionen wie Flächen über dem Parameter-Raum aufgespannt sind. Diese Funktionsflächen liefern ersatzweise die Systemantwort für die eingespeiste Parameter-Kombination.
- Vorteil
- Auf die Ersatzfunktionen können die gleichen Sample-Methoden angewandt werden, wie zuvor auf das Originalmodell.
- Der Umfang einer virtuellen Stichprobe kann sehr groß gewählt werden, da die Ersatzfunktionen um Größenordnungen schneller als die Originalmodelle rechnen.
- Damit können statistischen Aussagen zu den Ersatzfunktionen praktisch mit beliebiger Genauigkeit gewonnen werden.
- Nachteil
- Eigentlich interessieren den Anwender nicht die Aussagen zur Ersatzfunktion, sondern die Eigenschaften des zu untersuchenden Originals. Die Genauigkeit der statistischen Aussagen in Bezug auf das Originalmodell wird überwiegend durch die Genauigkeit der Approximationsfunktionen bestimmt.
- Die Residuen der Ausgleichsrechnung für eine vorliegende Stichprobe zeigen nur, wie genau die die Ausgleichsfläche in die vorhandene Punktwolke passt.
- Informationen zur Genauigkeit der Ausgleichsfläche in den Zwischenräumen der Punktwolke sind mit dem Polynom-Ansatz nicht zu gewinnen.
- Es ist somit schwierig, statistisch gesicherte Aussagen zum Originalmodell für kleine Fehlerintervalle zu erhalten.
Hinweis:
- Man darf nie vergessen, dass ein Originalmodell auch nur ein fehlerbehafteter Ersatz für das eigentlich zu untersuchende Original darstellt.
- Modellbasierte statistische Aussagen im Promille-Bereich sind in Bezug auf das Original immer sehr skeptisch zu betrachten!
- Die Response Surface Methode erzeugt hier eine weitere Modell-Hierarchie im Experimentierprozess.